- Argomento
- Lettere e Linguaggi
L’Università del Piemonte Orientale per il Vocabolario dinamico dell’italiano moderno
Studiosi dell'Università del Piemonte Orientale e di altri atenei nazionali hanno costruito un vocabolario "vivo", capace di tenere conto delle evoluzioni della lingua italiana nel presente e nel passato. Un corpus che si adatta alle esigenze degli utenti e l'uso di strumenti informatici messi a disposizione dall'Accademia della Crusca sono le fondamenta su cui nasce, e cresce, il VoDIM.
Data di pubblicazione
Un tempo i vocabolari venivano realizzati compilando manualmente migliaia di schede. Ci voleva una lunga lettura, tanti appunti, il lavoro faticoso di una squadra di operatori pazienti. Oggi i vocabolari sono frutto di informatica. Nascono dallo spoglio elettronico di corpora complessi, cioè di enormi quantità di testi, riuniti mediante un “bilanciamento”: ciò significa che un corpus deve essere “equilibrato”, deve contenere testi rappresentativi di diverse tipologie di scrittura. Deve possedere una certa quantità di testi letterari, ma anche una certa quantità di giornali quotidiani, di saggistica, di scritti pratici e tecnici, e così via. In questo modo il corpus diventa rappresentativo della realtà linguistica nella sua complessità.
Negli ultimi anni la Crusca ha messo in cantiere la realizzazione di un vocabolario elettronico dell’italiano postunitario, con l’obiettivo di descrivere la lingua moderna usando strumenti informatici nuovi.
L’Accademia della Crusca già prima del 2015, anno del nostro ultimo PRIN (progetto di ricerca di interesse nazionale), ha iniziato la costruzione di grandi corpora, in vista della ripresa del proprio lavoro lessicografico, iniziato nel 1612, proseguito per secoli, ma interrotto nel 1923, quando Mussolini tolse all’Accademia la responsabilità del Vocabolario, per assegnarlo poi all’Accademia d’Italia, nata appunto con il Fascismo. Nel dopoguerra, sparita l’Accademia d’Italia, la Crusca ritornò alla lessicografia, ma con un progetto diverso, limitato alla lingua antica.
Negli ultimi anni la Crusca ha messo in cantiere la realizzazione di un vocabolario elettronico dell’italiano postunitario, con l’obiettivo di descrivere la lingua moderna usando strumenti informatici nuovi. Il PRIN 2015 ha visto l’Università del Piemonte Orientale capofila di questo progetto lessicografico legato alla Crusca. Sono entrati nell’impresa vari atenei, sotto la direzione del P.I. Claudio Marazzini, allora professore ordinario di Linguistica italiana nel Dipartimento di studi umanistici. Erano nella squadra le Università di Catania, di Firenze, “L’Orientale” di Napoli, gli atenei di Genova, Torino, Milano e della Tuscia.
Ognuno aveva un compito preciso: si dovevano raccogliere e codificare testi selezionati, divisi tra le varie università in base alla tematica, e questi testi dovevano poi confluire in un grande corpus bilanciato per il VoDIM, il Vocabolario dinamico dell’italiano moderno. L’insieme dei dati raccolti ed elaborati doveva essere affidato definitivamente all’Accademia della Crusca, la più prestigiosa istituzione linguistica d’Italia, che ha sede a Firenze ed è un ente statale dipendente dal Ministero dei Beni Culturali (la lingua è un “bene culturale”, anche se molti non se ne rendono conto). Alla Crusca spettava il trattamento informatico finale dei materiali per la pubblicazione in Rete del VoDIM.
Ci si può chiedere che cosa significhi “vocabolario dinamico”. Cercheremo di spiegarlo in poche parole. Abbiamo visto che un corpus, per essere rappresentativo, deve essere “bilanciato” secondo una miscela equilibrata, adatta a rappresentare l’intera lingua della nazione. Questo vuol dire che non si devono commettere errori nella distribuzione dei materiali. Ad esempio, se il mio corpus contenesse il 90% di testi letterari (romanzi o poesie) avrei un effetto molto squilibrato, perché la lingua che usiamo tutti i giorni non è soltanto quella della letteratura. Ci vogliono anche le parole della politica, del diritto, dell’attualità, dello sport ecc. Però può accadere che chi consulta il vocabolario elettronico abbia bisogno di informazioni relativamente a un tipo specifico di linguaggio, per esempio proprio quello letterario, e allora gli può far comodo eliminare provvisoriamente dall’interrogazione tutto quello che letteratura non è. La nostra idea era dunque questa: costruire un vocabolario in cui il corpus si adattasse alle richieste dell’utente, assecondando le sue necessità. Un vocabolario del genere richiede ovviamente un lavoro di anni per essere portato a termine. Il suo allestimento non si è certo concluso con il PRIN 2015. È stato un vantaggio consegnare i materiali alla Crusca, un’istituzione che vanta ben 400 anni di storia, e che quindi dà le massime garanzie di continuità per la prosecuzione del progetto.
La lingua è un “bene culturale”, anche se molti non se ne rendono conto.
Come abbiamo detto, a ciascuna delle unità di ricerca del PRIN era affidato un settore particolare della lingua. L’Università del Piemonte orientale, oltre ai compiti di direzione generale, doveva allestire un corpus di testi scientifici. Oggi la maggior parte degli scienziati non usa più la lingua italiana. La lingua internazionale della comunicazione scientifica è l’inglese. Ma non è stato sempre così, e quindi abbiamo voluto dare voce lessicografica a fisici, medici, fisiologi e matematici che dagli anni dell’Unità d’Italia usarono brillantemente l’italiano nei loro studi (il progetto, come anticipato, non si occupa del periodo più antico, ma dell’italiano moderno postunitario).
Nessun altro dizionario generale italiano ha dato tanto spazio alla documentazione attinta da testi scientifici: nella nostra grande tradizione lessicografica, che è stata modello per tutta l’Europa colta, i letterati hanno sempre giocato la parte predominante. I nostri dizionari sono sempre stati squilibrati nella direzione della letteratura, fonte quasi unica per la compilazione delle voci. Questa caratteristica è evidente anche nell’ultimo grande vocabolario realizzato in molti volumi, il GDLI della UTET, il cosiddetto “Battaglia” (dal nome del primo direttore), concluso nel 2002. Insomma, scienziati e letterati, in Italia, non sono andati sempre d’accordo. Anzi, in molti casi si sono scontrati, soprattutto nella stagione dell’idealismo, dominata dalla filosofia e dalla figura di Benedetto Croce. Basti pensare alla celebre polemica di Croce contro i matematici, che si concluse con una definizione infelice: Croce li chiamò “ingegni minuti”, alludendo a una funzione tecnica subalterna delegata agli uomini di scienza, ai quali sfuggiva la visione generale del mondo. Dal tempo di Benedetto Croce, dalla dittatura della cultura umanistica e letteraria, la situazione si è rovesciata, e oggi sono spesso gli umanisti e i letterati a subire le conseguenze dell’incomprensione dei colleghi scienziati.
Tra i nostri scopi c’era quello di ristabilire, all’interno del grande vocabolario della lingua italiana, un giusto equilibrio tra lingua letteraria e lingua della scienza. Ecco perché abbiamo avviato spogli nuovi, in opere scientifiche trascurate dalla lessicografia tradizionale. Non si dovevano dimenticare quegli scienziati che, soprattutto negli anni vivacissimi che seguirono l’Unità d’Italia, erano stati utilizzatori importanti della lingua italiana, riuscendo a renderla ancora più grande, anche se letterati e lessicografi non hanno poi riconosciuto loro questo merito, e anche se oggi un italiano di media cultura non sa che cosa deve a questi uomini di scienza, e non conosce nemmeno i loro nomi.

Enrico Fermi Enrico Fermi è uno degli scienziati italiani che i ricercatori hanno considerato per ampliare il corpus di termini scientifici.
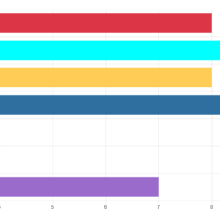
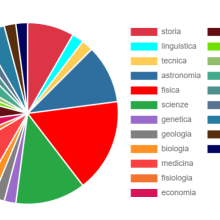
Ecco dunque il gruppo di ricerca del Piemonte orientale impegnato a identificare, in vari campi della scienza, i libri scritti in italiano degni di essere giudicati come i più importanti, per trasformali in testi elettronici consultabili e utilizzabili per il VoDIM. È stata l’occasione per recuperare libri bellissimi, assumendo una prospettiva da storici della scienza, ma applicata alla lingua. Sono entrati nella nostra collezione opere di astronomi come Schiaparelli, Secchi e Celoria, di fisici come Fermi e Persico, di matematici come Levi Civita e Enriques, di medici come Golgi, Bizzozero, Lombroso, Mosso, Brotzu, Guarda, Mottura, di naturalisti come Lessona e Canestrini (traduttore di Darwin), di genetisti come Montalenti, di chimici come Cannizzaro, di geologi come Sella, e via dicendo. Sarebbe bello illustrare il contributo dato da questi scienziati alla lingua italiana, mostrando quali parole hanno usato per scrivere delle proprie scoperte. Qui non avremo il tempo di farlo. Diciamo soltanto che il risultato del nostro lavoro è a disposizione: basta accedere al sito dell’Accademia della Crusca, nella sezione “Scaffali digitali”, e si apre la “Stazione lessicografica”, nella quale i materiali usciti dal nostro PRIN 2015 sono liberamente raggiungibili, sia in forma conglobata, sia divisi tra le unità del progetto. I dati possono essere analizzati attraverso una serie di grafici. Si può vedere per esempio la composizione diacronica del nostro corpus vercellese di lingua scientifica e, in un grafico a torta, le percentuali delle varie categorie di testi scientifici raccolti, ossia dei vari settori della scienza rappresentati nel corpus. Ecco i due grafici:
È possibile cercare nella “Stazione lessicografica” una parola, ottenendo le occorrenze nei testi, i quali, per essere resi interrogabili, sono stati trattati secondo particolari modalità, dopo essere stati salvati nella codifica XML-TEI, che garantisce l’utilizzabilità in futuro, perché si basa su standard concordati a livello internazionale. Ecco, per esempio, l’interrogazione per la ricerca di una tipica parola scientifica, il neutrone:

Ricerca il neutrone Vocabolario dinamico dell'Italiano Moderno
Al primo posto risulta l’occorrenza in un importante testo di fisica di Enrico Persico, uno degli ultimi manuali di rilievo anteriore alla conversione dei fisici alla lingua inglese. Persico, allievo di Orso Mario Corbino e amico di Enrico Fermi, usava ancora un ottimo italiano. La seconda occorrenza visibile nell’immagine è di Piero Bianucci. In questo caso non si tratta di uno scienziato, ma di un divulgatore, un giornalista molto bravo e molto conosciuto anche nel nostro Piemonte, collaboratore della rivista “Tutto scienze”. Nella colonna di destra, è possibile osservare la distribuzione delle occorrenze della parola nel corso del tempo: qui gli esempi partono dal 1936.
A questo proposito, relativamente alla datazione delle parole, ricordiamo che la nostra ricerca ha prodotto un altro strumento originale, uno strumento sviluppato da un’idea e dalle assidue schedature dell’allora assegnista Ludovica Maconi (ora professoressa associata): si tratta di ArchiDATA, un archivio elettronico di prime attestazioni italiane, allestito con lo scopo di retrodatare parole che i vocabolari di oggi, appoggiandosi a documentazione letteraria o, per i tecnicismi scientifici, a lemmari di dizionari ed enciclopedie novecentesche, ci dicono essere nate tra Otto e Novecento, ma che invece, con supplemento di indagine in altro tipo di fonti, scopriamo essere più antiche. Ad esempio, l’aggettivo emoglobinico è registrato nei repertori di riferimento come parola del secondo Novecento, ma in realtà è usato già negli anni Ottanta dell’Ottocento negli studi di Bizzozero; il sostantivo albuminuria è invece attestato prima dell’Unità d’Italia, negli anni Quaranta dell’Ottocento:
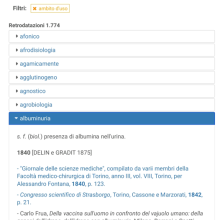
Le retrodatazioni di ArchiDATA sono a disposizione di tutti gli studiosi e lessicografi, per l’aggiornamento di dizionari storici ed etimologici, e sono preziose per lo studio del lessico tecnico-scientifico.
Ultima modifica 10 Novembre 2022